Spartinančiosios atminties algoritmai (LRU, LFU, ARC) — apibrėžimas ir tipai
Sužinokite spartinančiosios atminties algoritmų (LRU, LFU, ARC) principus, privalumus ir praktinius taikymo pavyzdžius — pasirinkite optimalų talpyklos pakeitimo metodą savo sistemai.
Talpyklos algoritmas – tai algoritmas, naudojamas talpyklai arba duomenų grupei valdyti. Kai talpykla prisipildo, algoritmas nusprendžia, kurį elementą reikia išmesti, kad būtų priimtas naujas. Talpyklos efektyvumą dažnai matuoja hit rate (kiek užklausų aptarnaujama iš talpyklos), o vartotojo patirtį lemia terminas latentinis laikas (latency) – per kiek laiko gaunamas talpyklos elementas. Talpyklos algoritmai visada balansuoja tarp pataikymo dažnumo (hit rate) ir delsos (latency), taip pat tarp išlaidų (pavyzdžiui, atminties/CPU) ir tikslumo priimant sprendimus.
Vaizdų galerija
7 Vaizdai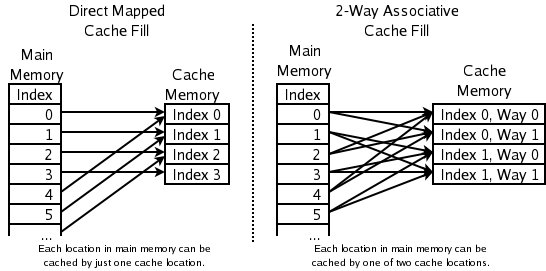



Optimalus sprendimas ir realaus pasaulio apribojimai
Efektyviausias talpyklos algoritmas būtų tas, kuris visada atmestų informaciją, kurios reikės vėliausiai ateityje. Šis idealus sprendimas vadinamas Beladžio optimaliuoju algoritmu arba aiškiaregystės algoritmu. Kadangi paprastai neįmanoma nuspėti ateities užklausų, šis algoritmas praktiškai neįgyvendinamas. Jo rezultatas naudojamas kaip teorinis minimumas: atliekant eksperimentus faktiškai pasirinkto algoritmo efektyvumas palyginamas su optimaliuoju.
Pagrindinės talpyklos keitimo strategijos
- Mažiausiai naudotas (LRU): pirmiausia ištrinami mažiausiai neseniai naudoti elementai. LRU reikalauja sekti elementų panaudojimo laiką arba tvarką. Populiarios įgyvendinimo technikos:
- naudoti dvigubą susietą sąrašą su žemėlapiu (O(1) operacijos),
- skaičiuotuvai (kiekvienam elementui saugomas laiko žymeklis arba rankena),
- Clock algoritmas (pseudolru)- pigesnė approximate LRU versija, kuri naudoja bitus ir rodyklę.
- Paskutinį kartą naudotas (MRU): pirmiausia išmetami vėliausiai naudoti elementai. MRU atrodo priešingai LRU ir kartais yra naudingas tam tikrose žaidimų arba duomenų bazių darbo krūvio situacijose (pavyzdžiui, duomenų bazių atminties talpyklose), kur naujausias elementas greitai nebenaudojamas.
- Pseudo-LRU (PLRU): kai LRU įgyvendinti sudėtinga arba per brangu, naudojamas PLRU, kuris dažnai naudoja mažai papildomų bitų (pvz., vienas bitas elementui arba mažesnė struktūra), kad apytikriai pasirinktų atmetamą elementą. PLRU yra greitas ir taupantis atmintį, bet ne visada tikslus.
Asociatyvumas ir vietos parinkimas
- 2 krypčių asocijuotoji: dažnai naudojama procesorių talpykloms, kai net PLRU yra per lėta. Naujo elemento adresas nusprendžia vieną iš dviejų galimų eilių (vietų). Iš šių dviejų vietų pašalinamas tas elementas, kuris yra „mažiausiai naudotas“ tarp jų. Tam paprastai pakanka vieno bito porai eilučių.
- Tiesiogiai žymima talpykla (direct-mapped): naudojama labai greitoms talpykloms. Kiekvienam adresui atitinka fiksuota talpyklos vieta – naujas elementas tiesiog perrašo buvusį. Tai labai greita, bet gali sukelti „konfliktų šokinėjimą“ (thrashing), jei keli dažnai naudojami adresai žymimi į tą pačią vietą.
Dažnio pagrindu veikiantys metodai
- Rečiausiai naudojamas (LFU): saugo kiekvieno elemento panaudojimų skaičių ir pirmiausia išmeta tuos, kurių skaičius mažiausias. LFU gerai veikia, kai populiariausi elementai ilgą laiką lieka aktualūs, bet turi trūkumų: be „seninimo“ (decay) LFU gali „užspaudinti“ talpyklą senais, bet anksčiau populiariais elementais. Dažnai pridedamas amortizavimo mechanizmas arba „apvalinimas“ (aging), kad adaptuotų į pokyčius.
- Adaptyvioji pakeitimo talpykla (ARC): nuolat balansuoja tarp LRU ir LFU, kad pagerintų bendrą rezultatą. ARC palaiko kelias eilutes (aktyviems ir „spėjimo“ — ghost) ir dinamiškai reguliuoja, kiek vietos skirti naujiems vs. dažnai naudojamiems elementams. Dėl adaptacijos ARC dažnai suteikia geresnį palyginamą našumą įvairioms darbo apkrovoms.
- Kelių eilių (MQ): daugelyje prioritetų ar trukmės eilių (Philbin ir Kai Li metodai) elementai keliauja per kelias eiles pagal jų panaudojimo pobūdį; nauji elementai pradeda „žemo“ prioritetų eilėje ir gali pakilti, jei vėl naudojami. Tokios struktūros padeda atskirti trumpalaikį ir ilgalaikį populiarumą.
Praktinės pastabos ir papildomi veiksniai
- Skirtingos įgijimo kainos: verta saugoti brangiai gaunamus duomenis (pvz., ilgo apdorojimo rezultatą, tolimų serverių užklausos rezultatus), net jeigu jie nėra dažniausiai naudojami.
- Elementų dydis: jeigu talpyklos elementai skiriasi dydžiu, gali būti prasminga atmesti vieną didelį elementą, kad tilptų keli mažesni, labiau naudingi elementai. Tam taikomi „size-aware“ algoritmai arba knapsack tipo heuristikos.
- Galiojimo laikas (TTL): elementai gali turėti iš anksto nustatytą galiojimo laiką (pvz., DNS, naujienų talpyklos, naršyklės talpykla). Jei elementas pasibaigęs, jį galima išmesti be papildomų sprendimų – tai sumažina reikalavimus talpyklos keitimo algoritmui.
- Senėjimas (aging): LFU ar kiti skaičiuojantys algoritmai dažnai naudoja periodinį „ senėjimą“, kad sumažintų senų populiarių elementų poveikį ir leistų adaptuotis prie naujų darbo krūvių.
Cache coherence ir paskirstytos talpyklos
Yra ir algoritmų, skirtų talpyklos darnai palaikyti: tai aktualu, kai tiems patiems duomenims naudojamos kelios nepriklausomos spartinančiosios atmintinės (pavyzdžiui, keli duomenų bazių serveriai atnaujina vieną bendrą duomenų failą). Tokiais atvejais sprendžiami papildomi klausimai: kaštai sinchronizavimui, užuominų (staleness) valdymas, invalidacija arba inkrementinis atnaujinimas. Paskirstytų talpyklų strategijos dažnai derina vietinės talpyklos politiką su komunikacijos ir nuoseklumo politika tarp mazgų.
Kaip pasirinkti tinkamą algoritmą
- Analizuokite darbo krūvį: ar dominavo trumpalaikiai pasikartojimai (LRU), ar ilgalaikis populiarumas (LFU)?
- Ar svarbi laikina vėlavimo mažinimo prioritetas ar mažesnės išlaidos (pvz., CPU/atmintis)?
- Ar elementai skirtingo dydžio arba skirtingos įsigijimo kainos? Jei taip, reikalingos size-aware ar cost-aware strategijos.
- Jeigu nėra aiškaus modelio arba darbo krūvis keičiasi – rinkitės adaptuojančius algoritmus (pvz., ARC, MQ), kurie dinamiškai perskirsto talpyklos vietas.
Apibendrinant, nėra vieno „geriausio“ algoritmo visoms situacijoms. Rinktis reikia atsižvelgiant į darbo krūvio charakteristikas, našumo reikalavimus ir techninius apribojimus. Praktikoje dažnai naudojami aproksimaciniai ar hibridiniai sprendimai (PLRU, Clock, ARC, 2Q, MQ), kurie suteikia gerą kompromisą tarp našumo ir išteklių naudojimo.

Klausimai ir atsakymai
K: Kas yra talpyklos algoritmas?
A: Spartinančiosios atminties algoritmas - tai algoritmas, naudojamas talpyklai arba duomenų grupei valdyti. Jis nusprendžia, kurį elementą reikia ištrinti iš talpyklos, kai ji yra pilna.
K: Kas yra pataikymo rodiklis?
A: Patenkinimo rodiklis apibūdina, kaip dažnai užklausa gali būti aptarnauta iš talpyklos.
K: Ką apibūdina uždelsimas?
A: Vėlavimas apibūdina, per kiek laiko galima gauti talpyklos elementą.
K: Kas yra Beladžio optimalus algoritmas?
A: Beladžio optimalus algoritmas, dar vadinamas aiškiaregystės algoritmu, yra veiksmingas spartinančiosios talpyklos algoritmas, pagal kurį visada atmetama informacija, kurios nereikės ilgiausiai ateityje. Šio rezultato paprastai negalima įgyvendinti praktiškai, nes reikia numatyti, ko prireiks tolimoje ateityje.
Klausimas: Kaip veikia mažiausiai neseniai naudotas (angl. Least Recently Used, LRU)?
A: LRU pirmiausia ištrina mažiausiai naudotus elementus, todėl reikia sekti, kas ir kada buvo naudojama, naudojant kiekvienos talpyklos eilutės "amžiaus bitus" ir stebint, kuri eilutė buvo mažiausiai naudota pagal amžiaus bitus. Kiekvieną kartą, kai naudojama talpyklos eilutė, atitinkamai pakeičiamas visų kitų talpyklos eilučių amžius.
K: Kaip veikia MRU (Most Recently Used)?
A: MRU pirmiausia ištrina vėliausiai naudotus elementus, ir šis spartinančiosios atminties mechanizmas paprastai naudojamas duomenų bazių atminties talpyklose.
K: Kokie kiti algoritmai taikomi spartinančiosios atmintinės darnai palaikyti?
A; Kai bendriems duomenims naudojami keli nepriklausomi talpyklos, pavyzdžiui, kai keli duomenų bazių serveriai atnaujina vieną bendrą duomenų failą, egzistuoja įvairūs algoritmai talpyklos darnai palaikyti.
Susiję straipsniai
Autorius
AlegsaOnline.com Spartinančiosios atminties algoritmai (LRU, LFU, ARC) — apibrėžimas ir tipai Leandro Alegsa
URL: https://lt.alegsaonline.com/art/15882
Šaltiniai
- usenix.org : usenix.org/legacy/events/fast03/tech/full_papers/megiddo/megiddo.pdf
- usenix.org : usenix.org